| Message |
|
|
shinobi wrote:
ola wrote:
Edit.
Soweit ich weiß, braucht man auch für PDFs einen PC mit japan. Spracheinstellung (außer es ist ein Bild und kein Text).
Moin,
Da täuschst Du dich.
Nein, da täuschst Du Dich.
Grundsätzlich gilt, dass Schriftarten mit Copyright nicht in einer PDF eingebettet werden dürfen, solange man nicht der Inhaber ist. D.h. man muss freie Fonts nehmen und diese dann auch einbetten. Standardmäßig geschieht jedoch keine Einbettung bei Word und Co. Verschiedene PDF-Drucker (auch der von Adobe) bieten aber an, auch Systemschriften einzubetten. Das wäre aber natürlich wie eben erwähnt nicht legal.
cYa,
FreakRob
|
 |
|
|
Hallo und ein herzliches Willkommen im Wadoku-Forum allerseits.
Du gibst recht wenig Informationen. Zuallererst einmal möchte ich feststellen, dass ich weiß, worin Dein Problem besteht und Dich verstanden habe. Das ist auf die Han-Vereinheitlichung des Unicode-Standards zurückzuführen. Wie Du richtig bemerkt hast, gibt es 漢字, die im Japanischen und Chinesischen identisch aussehen. Diese werden bei Dir "fehlerfrei" dargestellt. In Anführungszeichen, da es keine Fehler im klassischen Sinne sind, sondern das sogar so gewollt ist.
Nun hast Du uns nicht gesagt, wo Dein Problem eigentlich auftritt. Dein Browser scheint nicht das Hauptproblem zu sein, denn Du bemerkst nur "wie auch hier zu sehen". Du willst also nehme ich mal an, das ganze in einem Textverarbeitungsprogramm verwenden, z.B. Microsoft Word, Open Office etc. Du hast uns auch nicht gesagt, welche Version des Betriebssystem Windows Du verwendest.
Wie dem auch sei. Dein Problem rührt daher, dass Du zum Anzeigen des Zeichens den falschen Font verwendest. Für japanische Zeichen musst Du einen japanischen Font nehmen, für chinesische Zeichen einen chinesischen.
Was geschieht ist folgendes: Das IME-Pad zeigt standardmäßig in einem japanischen Font an (MS Mincho oder MS Gothic). Was aber am Ende eingegeben wird, ist bloß das (ambige) Zeichen, welches dann im darunter liegenden Font dargestellt wird. In Applikationen wie Word 2007 wird tatsächlicherweise ein Font verwendet, der zur Eingabemethode passt (unabhängig davon, welchen Font Du vorher ausgewählt hattest). Im Webbrowser Firefox wird die Anzeige über die Font-Einstellungen je nach erkannter Sprache getätigt.
Kurzum, Du musst bei Firefox und Co. die richtigen Font-Einstellungen treffen für japanische Texte. Für Textverarbeitungsprogramme musst Du auch den Anzeigefont ändern. Dann geht's und Du solltest das gewünschte Zeichen sehen. Sobald Du uns sagst, welchen Browser und welche Textverarbeitung etc. Du verwendest, lässt sich noch eine genauere Abfolge zur erfolgreichen Konfiguration beschreiben.
So, ich hoffe ich konnte Dir erstmal im Ansatz erklären, was schief läuft und warum. Anbei habe ich noch eine Testdatei im HTML-Format angehangen. Mit der kannst Du überprüfen, ob Dein Browser generell Font-Einstellungen für Japanisch und Chinesisch richtig eingestellt hat, jedoch u.U. Chinesisch bevorzugt, wenn keine Informationen über die Textsprache vorliegen. Die 漢字 「直」 sind jeweils mit der richtigen Sprache getaggt. Anbei auch die Ausgabe meines Webbrowsers. Bemerke, dass insgesamt vier verschiedene Fonts verwendet werden: Times New Roman für lateinischen Text, MS PGothic für Japanisch, SimSun für Chinesisch vereinfacht und MingLiu für Chinesisch traditionell.
cYa,
FreakRob
|
|
|
|
;). <-- Das ist ein Link. cYa, FreakRob
|
|
|
|
Niremori wrote:Wie kommst du darauf? (Bzw.: Wo steht das?)
Naja, ich meine, genau diese Onomatopoeia werden indirekt angesprochen. Ein stereotyper deutscher Hund bellt nun mal "wau wau" und nicht "gaf gaf". Interesssant ist allerdings, dass man wenn man diese anderen Stereotypisierungen kennt, diese auch meistens hören kann. Falls Du meintest, wo generell etwas zu Onomatopoeia steht, dann ist die Wikipedia-Seite ein guter Start. cYa, FreakRob
|
|
|
|
Ich glaube es geht dabei darum, dass ein deutscher Hund "Wau wau", ein englischer "bark bark" und ein russischer "gaf gaf" macht. Diese Onomatopoeia sind sehr verschieden pro Sprache.
cYa
FreakRob
|
|
|
|
Ist doch auf der von Dir verlinkten Seite sehr schön angegeben:
http://www.gotoh-museum.or.jp/collection/col_01/images/Genji_Kaisetsu_01.jpg
Der Teil direkt unter der von Dir verlinkten Geldscheinseite enthält den Text.
Wenn es Dir um den Text selbst geht, das steht eigentlich genau davor: 詞書 第一面(第一・二紙) すゝむし Einleitung Rolle 1, Blätter 1 und 2, Suzumushi von der 源氏物語絵巻 Genji Monogatari Emaki (Schriftrolle. Anscheinend gab es damals noch nicht den Unterschied der Betonung aufzuschreiben, sprich dakuten ゛ und handakuten ゜. Darum ist das Wiederholungszeichen (kurikaeshi) ゝ und nicht ゞ. Im Text ganz rechts steht, dass es sich dabei um den ersten Teil von Kapitel 38 handelt.
http://etext.lib.virginia.edu/japanese/genji/original.html, dort dann 38 Suzumushi und Abschnitt [2-2 8月15夜、秋の虫の論].
cYa,
FreakRob
|
|
|
|
Dein Bild ist Kalligrafie und sieht sogar ziemlich gut aus. Nun kannst Du es Dir ruhig tätowieren lassen =]
cYa,
FreakRob
|
|
|
|
Kann es sein, dass die ursprüngliche Unterscheidung nicht
ひらがなむだ、
カタカナムダ und
漢字無駄 war, sondern むだ、
ムダ und
無駄? Das würde für mich irgendwie viel mehr Sinn ergeben. Das sollen ja Steigerungen sein und es geht von einfach zu komplex, also von katakana zu hiragana zu kanji. Quasi also eine Versinnbildlichung der Verschwendung auf die verschiedenen Komplexitätsebenen durch die Benutzung von verschiedenen Schriftsystemen (Katakana lernen die Kids angeblich nach hiragana, aber fast alle Kinderbücher, die ich gesehen habe, haben nur katakana verwendet, da es einfacher für Kinder ist, die harten Kanten nachzumachen als die weichen Linien von hiragana.)
cYa,
FreakRob
|
|
|
|
Weder dōkan noch dokan haben irgendwie "Weg ist ein Kreis" als Bedeutung... Ich nehme an, dō ist 道. Das würde ich dann aber eher am Ende des Wortes erwarten...
EDIT: Scheint aus irgendeiner Karate-Terminologie zu kommen.Es gibt jedenfalls mehrere dōkan 道館, die noch einen Titel davor haben. Shidōkan (士道館), Shōdōkan (尚道館) habe ich auf die Schnelle gefunden. Vielleicht meinst Du ja das, obwohl das noch viel weniger mit Kreis zu tun hat. Dafür halt mit Gebäude...
cYa,
FreakRob
|
|
|
|
Lehrling wrote:@FreakRob
Was meinst du mit, ein L hört sich wie ein R an? Wenn ein Japaner ein Fremdwort mit einer Silbe, die ein L beinhaltet, durch ein R ersetzt, spricht er sie, so habe ich es immer erlebt, als R. Ich habe noch nie einen Japaner ein L aussprechen hören, wenn ein Wort mir einem R transkribiert wurde. Natürlich können sie ein L sagen.
Du hast mich nicht richtig verstanden. Ich rede nicht davon, wie es transkribiert wird. Das L wird nun mal nach den japanischen Lauten zum R hinzugeordnet. Ich z.B. kann kein so leicht gerolltes R sprechen. Habe ich stattdessen aber (mich wie ein kleines Mädchen fühlend) ein L gesprochen, gab es nie Probleme, weil alle Japaner es sofort als ein R erkannt haben. Dabei geht es nicht um irgendwelche lateinischen Wörter und auch nicht, wie sie geschrieben werden, sondern bloß, wie ich den Laut, den ich von mir gebe, verstehe und wie er verstanden wird.
Z.B. ist mein Vorname Robert, was ja schwer zu raten war. Immer wenn ich ロベルト (weil ich das dem Deutschen näher empfinde und so mag) gesagt habe, so wie ich es für richtig halte, kam grundsätzlich ホベルト oder ゴベルト bei raus. Die Leute haben sich schon gewundert, was das für ein komischer Name ist... Und das ist mir kein einziges Mal passiert, wenn ich (für mich offenkundig) ein L gesprochen habe, weil das gleich als R erkannt wurde, mein R aber anscheinend wahlweise (auch mit anschließendem Vokal unterschiedlich) als G oder H empfangen wurde.
Insofern ist das wirklich eine reine Trainingssache. Man kann trainieren diese Laute auseinander zu halten und das tuen ja auch viele Japaner, Chinesen etc. die dann z.B. beim Englischlernen merken, dass es da doch gewisse Unterschiede gibt. Und dann kommt langsam das Verständnis. Es ist nicht so, alsob die Ohren wirklich beim L und R denselben laut hören, aber es hört sich so an, weil es so antrainiert wurde mit dem Spracherwerb seit dem frühen Kindesalter. Diese Phoneme bilden sich heraus und man kann auch im Erwachsenenalter lernen, Phoneme auseinander zu halten und auch von sich zu geben. Es gibt z.B. Leute, die das komplette IPA auswendig können und wissen, welches Zeichen welchem Laut entspricht (nach Vokal, vor Vokal, zwischen zwei Vokalen) und diese auch produzieren können. Wieviel das hilft ist eine andere Frage...
Na jedenfalls ist es tatsächlich so, wie z.B. beim "th", dass es sich wirklich so anhört, bis man nach einiger Zeit den Unterschied hört und dann irgendwann auch mal selbst produzieren kann. Ist quasi wie beim gerollten R. Ich kann das nicht (und hatte z.B. wirklich Probleme mit meinem Russisch), kann es von einem nicht-gerollten R unterscheiden und sicherlich auch irgendwann produzieren. Dabei weiß ich, wie meine Zunge sein muss, wie die Atmung sein muss, allein, ich kriege es nicht hin. Ich weiß auch, wie z.B. im Japanischen die Laute verschoben sind, kann soweit ganz gut hören und auseinander halten, allein, ich kann sie nicht 100%ig nachmachen. Und das kommt mit Training.
Lehrling wrote:Deine Grafiken kann ich leider nicht lesen, da kenne ich mich nicht aus. Das geht über ein normales Sprachstudium hinaus.
Ich glaube nicht, dass man dafür unbedingt ein Sprachstudium braucht. Ich bin auch bloß interessiert und habe zugegebenermaßen eher Talent beim geschriebenen als beim gesprochenen gehabt, weil ich viele Laute einfach nicht produzieren kann. Die Grafiken sind sogenannte Vokaltrapeze. Lustigerweise habe ich keines für das Deutsche gefunden, dafür aber sogar Polnisch, Russisch, Schwedisch, Japanisch, Norwegisch etc. Naja, will sagen: Du siehst z.B. das "a" in Schwedisch und in Japanisch in der Grafik. Sie sind leicht verschoben, aber so nahe beieinander, dass es z.B. selten Probleme geben wird, dass ein Japaner ein schwedisches A nicht versteht. Umgedreht aber, gibt es z.B. keinen einzelnen Laut im Schwedischen, der dem jap "e" gleicht. Nun wird ein Schwede, der die Sprache lernt, vermutlich eines seiner e-Laute benutzen. Das kommt dann, je nachdem wie weit es weg vom jap. "e" ist, zu Verständnisschweirigkeiten bis hin zu Falschdeutungen. Z.B. wenn der Schwede jetzt "I" oder "Y" nimmt, wenn er ein jap. "i" möchte, kann es durchaus dazu kommen, dass ein jap "e" ankommt. Nun sind das wie gesagt Vokaltrapeze. Es gibt noch gesondert andere Laute für die Konsonanten je nachdem, welcher Vokal ihnen vorausgeht, folgt etc. Dazu gibt es anscheinend keine guten Diagramme sondern bloß die blöden Tabellen mit den hochwissenschaftlichen Begriffen, die kein Normalverbraucher versteht. Jedenfalls wird es da wie gesagt, noch ein bisschen komplizierter, wenn man die Zuordnung von Lauten auseinander nehmen will. Dazu eben mein obiges Beispiel, unter welchem Namen ich schon weggegangen bin... Fast hätte auf meinem Zeugnis der Sprachschule "Hobert" gestanden 
cYa,
FreakRob
|
|
|
|
Nunja, das ist nicht ganz richtig. Es hört sich tatsächlich gleich an. Für mich war das z.B. beim "th" im Englischen der Fall. Es hörte sich einfach wie so ein deutsches "s" an. Zis, zat and zere sind im Englischen beliebt um diesen Deutschen Aktzent nachzumachen.
Das ganze kann man natürlich wissenschaftlich begründen:
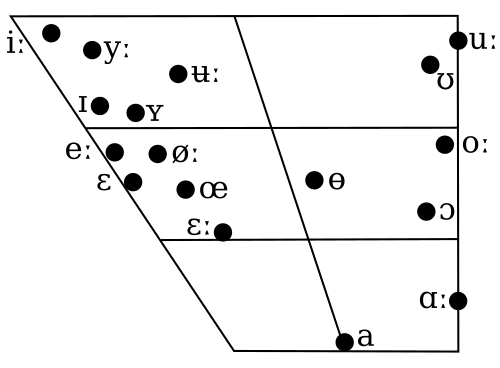
Das sind die schwedischen Laute. Also die Laute, die ein Schwede unterscheiden kann. Die einzelnen Felder haben unterschiedliche Bedeutungen, auf die ich hier nicht näher eingehen möchte. Es ist wohl nachgewiesen (hat man uns in der Uni erzählt), dass die Schweden die meisten Laute auseinanderhalten können. Babies können angeblich noch mehr auseinanderhalten (unabhängig in welche Kultur sie geboren werden) und die nicht-benutzten Laute fallen dann halt in den ersten Lebensjahren stark zusammen.
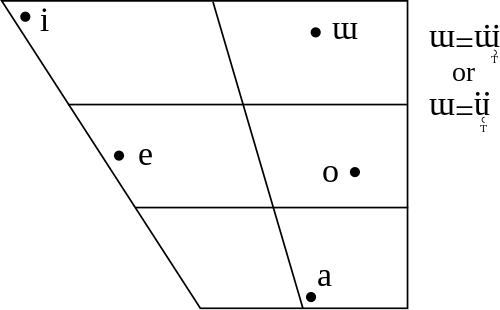
Die sind die Laute im Japanischen. Man sieht: deutlich weniger. Alle Laute, die nun empfangen werden müssen in eine Kategorie eingeteilt werden. Das kann man sich ganz vereinfacht so vorstellen: Man ordnet den gehörten Laut auf diesem Diagramm an und sucht den nächsten Nachbarn. Das ist dann ungefähr die Zuordnung, die ein (untrainierter) Muttersprachler macht. Also ja, ein L hört sich wirklich wie ein R an. Erst mit der Zeit und intensivem Training können sie auseinander gehalten werden. Und selbst dann kann es sein, dass man sie nicht selbst produzieren kann.
Ich habe ein wenig geschummelt, weil es diese Diagramme bloß für Vokale gibt. Man kann sich das ganze für Konsonanten aber ungefähr auf dieselbe Art vorstellen. Bei Konsonanten kommen üblicherweise noch Paarungen mit Vokalen ins Spiel, so, dass kein so einfaches Diagramm erstellt wird.
cYa,
FreakRob
|
|
|
|
Also generell wird ein ausgepsrochenes L und genau wie ein R betrachtet in Japanischen. Die Unterscheidung dieser Laute geht mit der Zeit verloren, da sie im Japanischen zusammenfallen. D.h. die meisten Japaner müssen sich diese Unterscheidung erst wieder antrainieren.
Ich vermute daher, dass Du etwas ganz anderes meinst: Manche Rs verschwinden, wenn sie ein Japaner ausspricht.
Z.B. wird der Vorname Robert meist ロバート wiedergegeben, was ungefähr der Anpassung der englischen Aussprache an das Japanische entspricht. Hier ist jetzt also das hintere R "verschwunden" weil der Laut davor einfach gedehnt wird. Dann gibt es natürlich noch die Sache, dass viele Laute, die auf -u enden, einfach manchmal "verschluckt" werden. D.h. viele Japaner hören keinen Unterschied, wenn man ル und r z.B. am Wortende spricht. Das kann man vorallem feststellen, wenn man sich die Wortenden von vielen lateinischen Wörtern ansieht, die nicht auf einen Vokal enden. Für alle Silben wird う段 genommen, außer für た行, da wird ト genommen.
Also ist das vielleicht die Erklärung, die Du suchst. Ergo, warum man bei Haribel das り so stark hört, das ル aber nur als r und nicht als ru.
cYa,
FreakRob
|
|
|
|
Aha. Oho. Verstehe. Also nicht.
Lass mich das rekapitulieren: Du hast eine Bilddatei gesendet bekommen, die keine Textdaten enthält. Bist in der Umwandlung mit einem OCR-Programm rübergefahren, dass nur lateinische Schrift erkennt und wunderst Dich allen Ernstes, dass das Japanische nicht erkannt wurde?
cYa,
FreakRob
|
|
|
|
Chobyter wrote:ありがとうご やいます。 
Achtung: Japanisch nutzt das englische Tastaturlayout
cYa,
FreakRob
|
|
|
|
Das kannst Du entscheiden. Bei den Home-Versionen ist sowieso kein Outlook dabei.
Bei der Installation kannst Du angeben, was mit den alten Versionen passieren soll (Deinstallieren und nur neue installieren, oder eben nebeneinander installieren).
cYa,
FreakRob
|
|
|
|
|
|